


 Your new post is loading...
Your new post is loading...

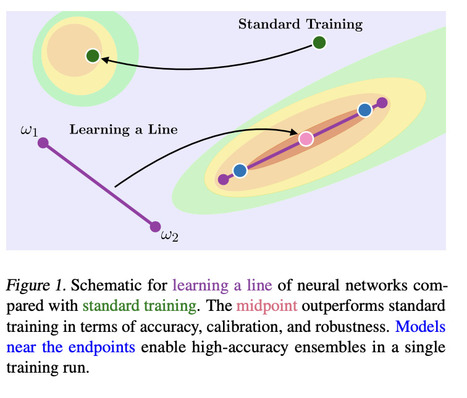

"This work is motivated by the existence of connected, functionally diverse regions in solution space. In contrast to prior work, our aim is to directly parameterize and learn these neural network subspaces from scratch in a single training run. [...] we have trained lines, curves, and simplexes of high-accuracy neural networks from scratch."






Interesting paper exploring the objective landscape specifically the relationship between subspaces of the loss function where neural networks (here ResNets) converge. Wortsman et al. assume the optimized weights of neural networks are connected through lines, Bezier curves or simplexes during different training iterations. They propose an algorithm to directly learn a connected subspace of the loss function rather than a single set of optimized weights. Their final parameters correspond to the midpoint of this subspace which "can boost accuracy, calibration, and robustness to label noise."
Overall, this paper shows the potential for optimization gains from simple assumptions about the geometry of a network's loss function. It would be worth exploring similar approaches for the weights & subspaces learned within a network.