


![[2303.06349] Resurrecting Recurrent Neural Networks for Long Sequences - Orvieto et al. (ETH & DeepMind) | The Future of Artificial Intelligence | Scoop.it](https://img.scoop.it/b4Wg6QuolUC_Tv4E9P7naTl72eJkfbmt4t8yenImKBVvK0kTmF0xjctABnaLJIm9)
From
arxiv
"Recurrent Neural Networks (RNNs) offer fast inference on long sequences but are hard to optimize and slow to train. Deep state-space models (SSMs) have recently been shown to perform remarkably well on long sequence modeling tasks, and have the added benefits of fast parallelizable training and RNN-like fast inference. [...] Our results provide new insights on the origins of the impressive performance of deep SSMs, while also introducing an RNN block called the Linear Recurrent Unit that matches both their performance on the Long Range Arena benchmark and their computational efficiency."


 Your new post is loading...
Your new post is loading...

![[2206.03945] Challenges in Applying Explainability Methods to Improve the Fairness of NLP Models | The Future of Artificial Intelligence | Scoop.it](https://img.scoop.it/u8QC_rM1YADr6siA_SGBuzl72eJkfbmt4t8yenImKBVvK0kTmF0xjctABnaLJIm9)

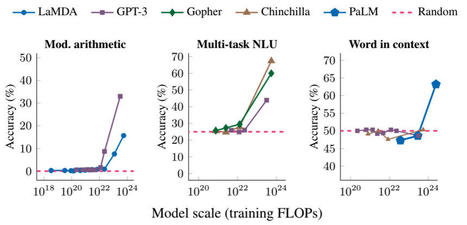
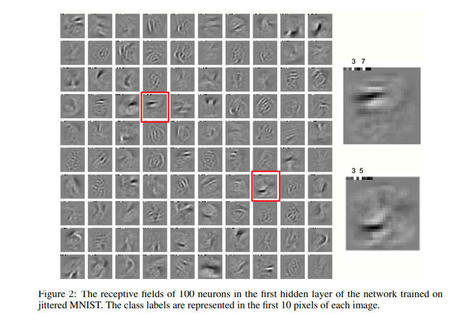



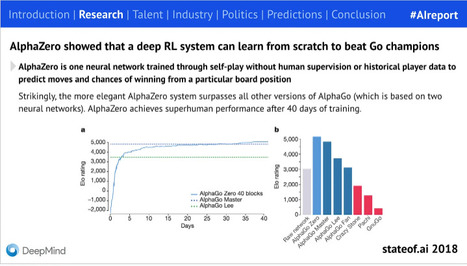











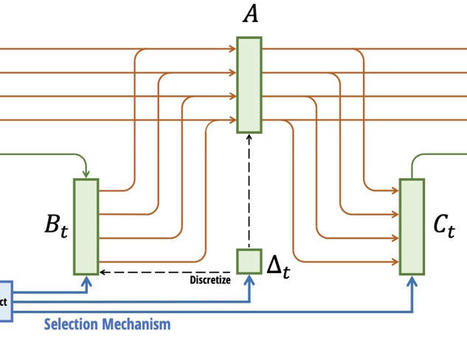
All the recent generative AI breakthroughs rely on transformers: OpenAI's GPTs, Meta's Llama, Mistral, Google's Gemini... however they are far from optimal due to their quadratic scaling with sequence length resulting in costly training. In contrast, RNNs scale linearly with sequence length but suffer from exploding and vanishing gradient problems. SSMs on the other hand have shown a lot of potential for modeling long-range dependencies. Orvieto et al., show the performance and efficiency of deep continuous-time SSMs can be matched with a simpler architecture: deep linear RNNs. Using linear hidden state transitions, complex diagonal recurrent matrices and stable exponential re-parametrization, the authors successfully address the failures of RNNs on long sequences. They match S4 results on Path Finder (sequence length = 1024) and Path Finder X (sequence length = 16k). Their reliability on linear recurrent units allows for parallelizable and much faster training.
Overall this paper motivates the search for RNN-based architectures and challenges the Transformer supremacy. SSM models are also emerging as an alternative.